由香港中文大學、Adobe Research及約翰霍普金斯大學研究人員共同開發的新型AI模型「EditVerse」,最大突破在於試圖打破傳統圖像編輯與影片編輯之間存在的巨大鴻溝,提出了一個統一的框架,讓使用者能以類似編輯圖片 (P圖) 的直覺操作,針對影片進行複雜的細節編輯與生成。

研究團隊指出,過去AI影片編輯之所以發展受限,主要在於架構隔閡 (模型多為圖像或影片專用) 與數據稀缺 (高品質、帶標註的影片數據遠少於圖像),而此款名為「EditVerse」的AI模型目標便是同時解決這兩大難題。
核心技術:通用視覺語言與上下文學習
EditVerse的核心方法論包含:
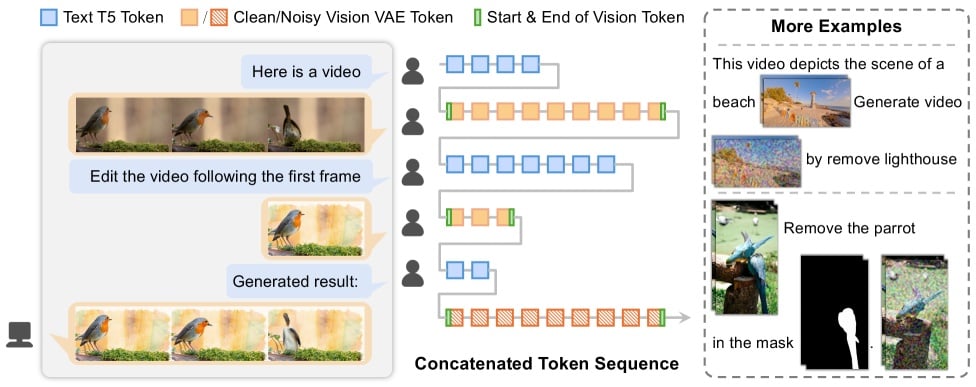
• 創造「通用視覺語言」:模型創新地將文字、圖片、影片全部轉換為一種統一的、一維的「Token序列」 (數據流)。使得AI能用同種方式理解和處理不同模態的視覺資訊。
• 強大的「上下文學習能力」:基於Transformer模型架構與全自注意力機制 (Full Self-attention),EditVerse能將包含指令、原始畫面的整段Token序列拼接在一起處理,透過全自注意力機制精準理解各部分之間的關聯 (例如指令文字、影片中的特定物件、參考圖片中的風格等),而此設計也使其能靈活處理不同解析度與時長的輸入。
• 搭建「知識遷移橋樑」:由於採用統一框架,EditVerse能將在海量圖像編輯數據中學到的知識 (如風格、特效),無縫遷移並應用於影片編輯任務,大幅緩解了影片數據稀缺的問題。
克服數據稀缺,建立EditVerseBench評測基準
為解決訓練數據不足的問題,研究團隊建立了一條數據生產線,利用多種專用AI模型先自動生成大量影片編輯樣本,再透過視覺語言模型 (VLM)進行篩選,最終產生了23.2萬個高品質影片編輯樣本。
這批數據與600萬圖像編輯樣本、390萬影片生成樣本等混合訓練,強化了模型的知識遷移能力。
同時,為科學評估模型效果,團隊也推出了業界首個針對指令式影片編輯的綜合評測性能標準——「EditVerseBench」。該性能標準包含100個不同解析度的影片,涵蓋20種編輯任務。

效果超越Runway,展現「涌現能力」
在EditVerseBench性能測試上,EditVerse在多項自動化評估指標 (包含影片品質、文字對齊、時間一致性、VLM評分等)上,全面領先於現有的開源模型 (如 TokenFlow、InsV2V等)。
更值得注意的是,在最接近人類偏好的VLM評分 (由GPT-4o進行評估),EditVerse的表現甚至超越了閉源的商業模型Runway Aleph。而在真人評測環節中,EditVerse也獲得了51.7%的用戶偏好度,勝過Runway Aleph。
研究人員更發現,EditVerse展現令人驚喜的「涌現能力」 (Emergent Ability)。即使其影片訓練數據中並未包含特定的「材質變換」或「特效添加」樣本 (例如將烏龜變成水晶、天空上加延時效果),模型依然能理解指令,並且成功完成任務。
透過消融實驗 (移除圖像編輯數據後模型能力大幅下降),團隊證明了這種「無師自通」的能力,主要來自於模型從海量圖像數據中學到的深層視覺原理,並且成功將其遷移至影片編輯領域。
創作新紀元
EditVerse的出現,不僅提供了一個強大的新工具,更可能預示著一個從分離走向統一、從繁瑣走向簡潔的全新內容創作範式的到來,有望將專業級的影片編輯能力普及給更多創作者。
目前相關論文、項目主頁與測試代碼皆已公開。