Meta AI FAIR團隊稍早發表其在自動語音辨識 (ASR) 領域的最新重大成果:「Omnilingual ASR」。這是一套號稱能為超過1600種語言提供自動語音辨識能力的模型套件,其規模與品質均達業界新高。
![]()
Meta強調,此舉將透過一個通用的轉錄系統,解決ASR技術與資源過度集中在少數高資源語言的問題,讓高品質的語音轉文字技術能惠及代表性不足的語言社群,打破數位鴻溝。
導入70億規模參數wav2vec 2.0,同步開源模型與資料集
配合此次發表,Meta同步開源了一系列相關的關鍵資產 (均在Apache 2.0許可下發布),包含:
• Omnilingual ASR模型家族: 提供多種尺寸,從專為低功耗裝置設計的3億組參數的輕量級版本,到提供頂級精度的70億組參數模型。
• Omnilingual wav2vec 2.0 基礎模型: 一個擴展至70億組參數的大規模多語言語音表徵模型 (Speech Representation Model),可作為ASR之外其他語音任務的基座。
• Omnilingual ASR Corpus (語料庫): 一個大型資料集 (CC-BY 許可),包含了350種服務欠缺 (under-served) 語言的轉錄語音。
LLM-ASR架構達成最先進模型,78%語言錯誤率低於10%
為解決ASR擴展的技術瓶頸,Omnilingual ASR引入了兩種架構。首先,團隊將其wav2vec 2.0語音編碼器 (encoder) 首次擴展至70億組參數,從大量未轉錄的語音中生成豐富的多語言語義表徵。
接著,團隊建構了兩種解碼器 (decoder) 變體:一種是傳統的CTC (連接時序分類Connectionist Temporal Classification);另一種則是利用了 Transformer解碼器,稱為「LLM-ASR」。
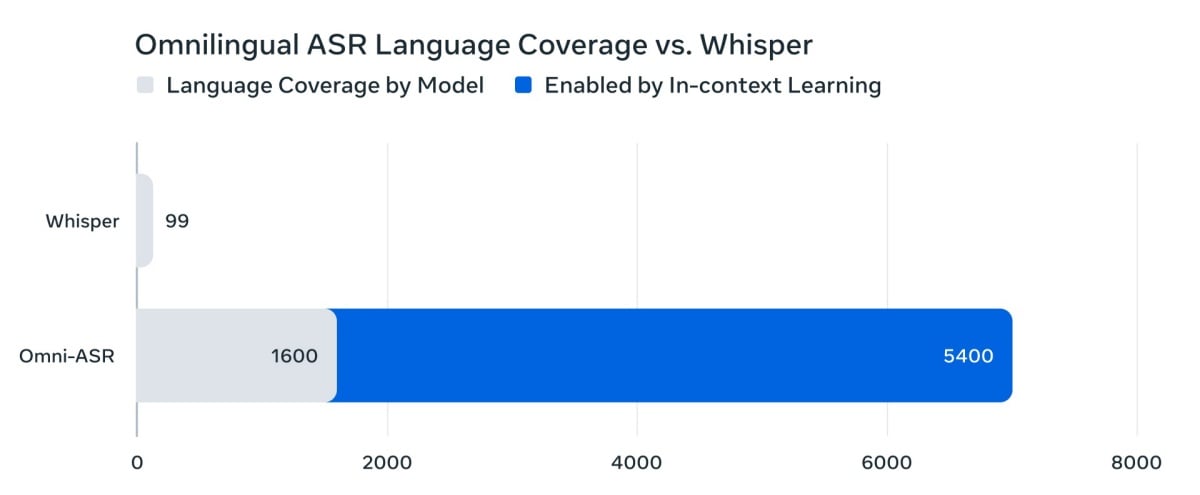
根據Meta公布研究論文,採用LLM-ASR方法的70億組參數系統,在超過1600種語言上達到了最先進模型效能 (SOTA,State-of-the-Art),其中78%的語言其字符錯誤率 (CER) 低於10%。
導入「自帶語言」(Bring Your Own Language) 概念
此次Omnilingual ASR最大的突破之一,在於改變了新增語言的傳統範式 (paradigm),引入了「自帶語言」 (Bring Your Own Language)的概念。這得益於其受LLM啟發的系統,導入了強大的「上下文學習能力」 (in-context learning)。
實務上,這意味著使用一種目前不被支援語言的用戶,僅需提供少數幾個成對的音訊-文本樣本 (audio-text samples),AI 就能透過這些上下文範例,獲得可用的轉錄品質,而無需進行大規模的模型微調 (fine-tuning)、專業知識或高階運算資源。此舉被視為能讓「社群驅動」 (community-driven) 的語言擴展成為可能。
攜手在地夥伴,收集350種低資源語言
為覆蓋那些幾乎沒有數位足跡的語言,團隊除了整合公開資料集,也與在地組織合作 (例如Mozilla基金會的Common Voice、Lanfrica/NaijaVoices等),直接與當地社群協作,招募並補償母語者提供語音紀錄。
這部分委託收集的語料庫作為Omnilingual ASR Corpus發布,是目前針對超低資源 (ultra-low-resource) 自然語音ASR所組建的最大資料集之一。
目前,相關的模型、資料集、轉錄工具Demo與語言探索Demo,都已透過GitHub、Hugging Face與Meta AI網站等管道對外釋出。