Elon Musk 旗下的人工智慧公司 xAI 採突襲戰術,悄然上線了全新的 Grok 4.1 模型系列。此次更新分為標準版的 Grok 4.1 ,以及支援深度推理的 Grok 4.1 Thinking,兩者目前均向使用者免費開放。
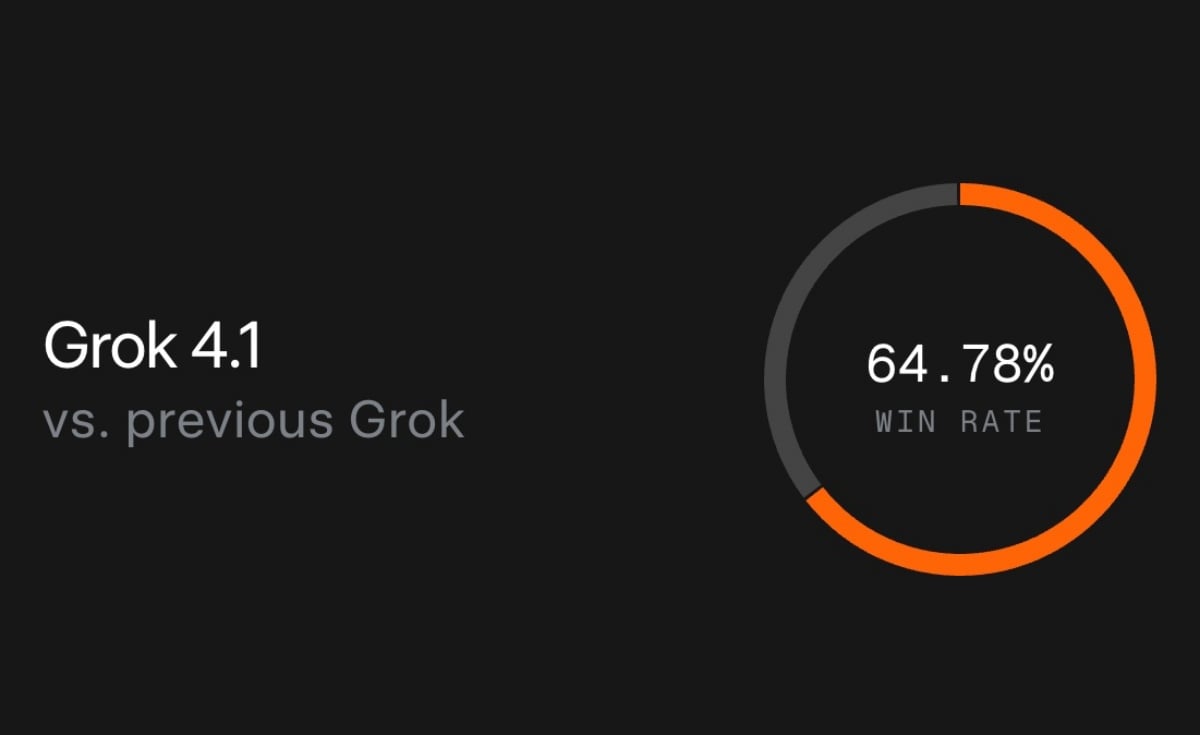
LMArena 霸榜前二,施壓 Google Gemini
在 LMArena 排行榜中,Grok 4.1 Thinking 以 1483 Elo 分的成績強勢空降榜首,而切換至非推理模式的標準版 Grok 4.1 也緊隨其後殺入第二名。
值得注意的是,原先表現不俗的 Google Gemini 2.5 Pro 目前滑落至第三,與榜首的 Grok 4.1 Thinking 相差足足 31 分。此舉無疑給 Google 即將推出的 Gemini 3.0 帶來了不小的競爭壓力。
創意寫作能力躍進,僅次 GPT 5.1
新版模型在創意寫作能力上也有顯著提升,根據 Creative Writing v3 的跑分結果,Grok 4.1 Thinking 與 Grok 4.1 的表現僅次於 OpenAI 的 GPT 5.1,成功擊敗包含 OpenAI o3、Claude Sonnet 4.5 ,以及 Kimi K2 Instruct 等強勁對手。
幻覺大幅降低,資訊錯誤率減 7 成
除了效能與創作力,xAI 也大幅優化了模型的準確性。數據顯示,相較於前一代的 Grok 4 Fast,Grok 4.1 的資訊錯誤率大幅下降了約 7 成。在 AI 容易出現的「幻覺」 (hallucination) 問題上,發生機率也從原先的 12.09% 顯著降低至 4.22%,大幅提升了其實用性與可靠度。