AWS宣布推出搭載旗下3nm製程AI晶片Trainium3的Amazon EC2 Trn3 UltraServers伺服器,目標解決當前AI模型訓練與推論時面臨的成本與算力瓶頸,官方數據顯示,其運算效能較前一代設計提升高達4.4倍,能源效率更提高40%,並且試圖透過更具競爭力的使用價格,讓更多企業能負擔得起訓練大規模AI模型所需的基礎設施。

單機配置144顆Trainium3晶片、延遲低於10微秒
Amazon EC2 Trn3 UltraServer的核心在於其高度整合架構,單一系統可容納多達144顆Trainium3晶片,提供高達362 FP8 PFLOPs的AI算力,並且從即日起正式上線。


為了應對分散式運算的通訊瓶頸,AWS導入新的NeuronSwitch-v1與增強版Neuron Fabric網路技術,將晶片間的通訊延遲壓低至10微秒 (μs)以下,對於需要大量數據流動的代理式AI (Agentic AI)或混合專家模型 (MoEs) 尤其重要。
AWS更指出,透過EC2 UltraClusters 3.0設計,客戶可連接數千台UltraServers伺服器,將其擴展至具備100萬顆Trainium晶片數量的超大運算叢集,規模更是前一代的10倍。

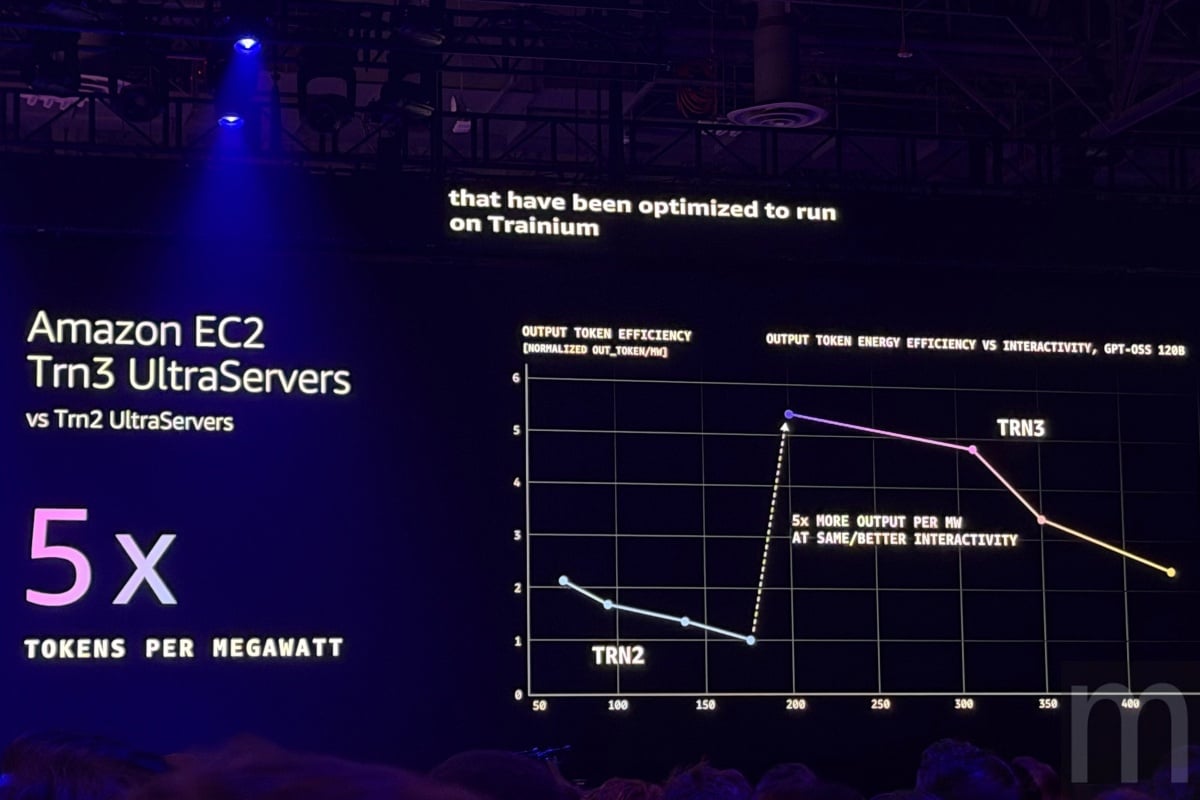
Decart、Anthropic率先採用,成本降低50%
在實際應用案例中,AWS列舉了多家合作客戶的成效。
其中,專攻生成式AI影片的Decart表示,使用Trainium3進行即時影片生成的推論速度快了4倍,而成本僅為原先使用GPU加速運算的一半。而諸如Anthropic、Karakuri、Ricoh (理光)等客戶,也透過Trainium晶片運算能力成功降低高達50%的訓練與推論成本。
另一方面,AWS更透露與Anthropic合作的「Project Rainier」計畫更新狀況,該計畫已連接超過50萬顆Trainium2晶片,成為全球最大的AI運算叢集之一,規模更是Anthropic訓練上一代模型時的五倍。

預告Trainium4將支援NVIDIA NVLink Fusion互連技術,打破陣營藩籬
在展望未來時,AWS更確認正在開發下一代Trainium4晶片,除了預期效能將再提升6倍 (在FP4運算時)、記憶體頻寬提高4倍、記憶體容量可擴增2倍之外,更說明此晶片將支援NVIDIA NVLink Fusion高速互連技術。
意味著未來Trainium4、Graviton處理器將能與NVIDIA GPU在通用的MGX機架內無縫協同運作,打破了過往自研晶片與GPU陣營壁壘分明的界線,為客戶提供更具彈性的混合架構選擇。